
Fraud Rules Engine
Detect and Prevent Suspicious Activity
Financial institutions typically have thousands of customers who conduct many more daily transactions. And in an age where digital technology is prominent, it doesn’t take long at all for a criminal to make a series of illegal transactions. So how does an FI monitor and evaluate all of those activities while still being able to take action on the suspicious ones in time?
A key part of a fraud detection system that can handle these volumes and speeds is a rules engine. This is a piece of decision software that a financial institution’s anti-fraud and AML teams can program to analyze transactions for certain criteria, then take specific actions based on those criteria’s presence or absence. After all, computers can handle processing large volumes of data much faster than humans can, allowing fraud fighters to keep up with the crooks.
Here, we’ll explain a bit more about what a rules engine is, including how it works and how (and why) FIs use rules engines to bolster their anti-fraud and anti-money laundering operations.

What is a Rules Engine?
A rules engine is a software program that automatically makes decisions and performs actions when certain conditions are met. When a condition is triggered, a rules engine can be trained to look at the circumstances of that condition and make different decisions based on these variables.
What is a Fraud Detection Rules Engine?
A fraud detection rules engine is decision-making software designed to determine if certain financial activity is suspicious or even criminal. It can be programmed to comply with mandatory AML regulations and identify fraud trends, then tweaked to behave in line with a financial institution’s risk appetite.
In some cases, the rules engine simply flags suspicious activity for analysts to investigate, as opposed to actually actioning a case itself. Either way, rules engines are ideally suited to identify instances of fraud or money laundering, and both fraud teams and compliance teams can use them to detect suspicious activities.
How a Fraud Rules Engine Works
A rules engine works in three basic steps:
- An event (such as a transaction) meets a condition (or set of conditions) that triggers the rules engine.
- The rules engine evaluates the event for certain criteria, according to its rules.
- Based on what criteria are or aren’t satisfied, the rules engine chooses a certain action to take in response to the event.
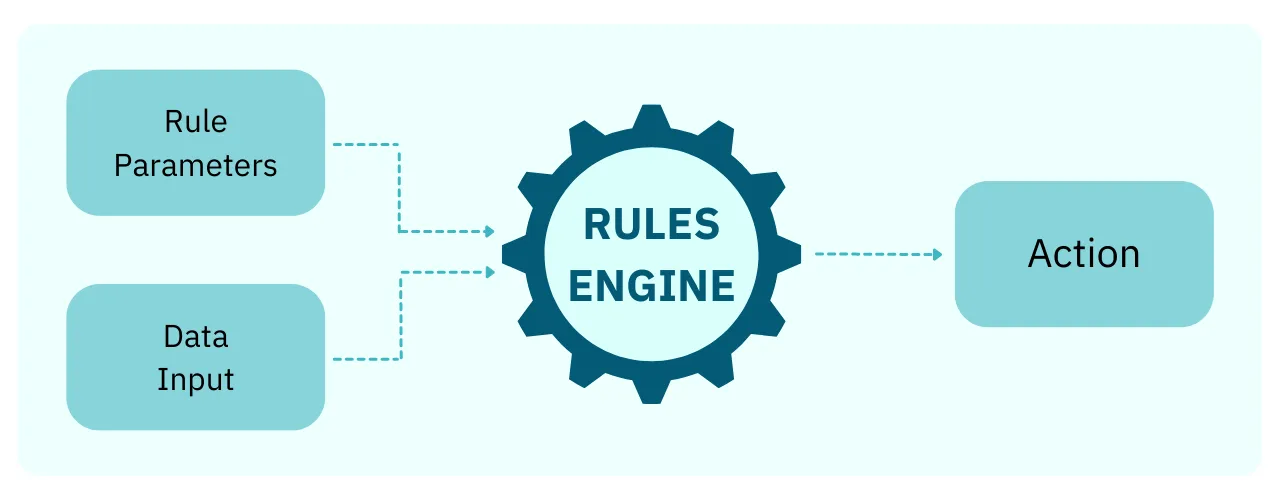
For the most part, the action a rules engine takes is predetermined—and programmed—by the risk and compliance team. However, modern rules engines that use machine learning can actually be programmed to decision cases on their own.
The rules themselves can be anything from simple “true or false” comparisons to complex algorithms that weigh multiple factors before making a decision. We’ll discuss some of these differences a little later.
Benefits of Using a Rules Engine for Anti-Fraud and Anti-Money Laundering
So why should financial institutions use rules engines as part of their anti-fraud and AML operations? Some of the main reasons include the following:
- Simple to deploy and change: A rules engine can reduce money laundering and fraud detection to sets of simple steps that are fairly easy to implement and modify. The latter point is useful if an FI wants to proactively detect a new fraud trend, or has to adapt to new or adjusted AML regulations.
- Automates repetitive tasks: Many fraud and money laundering detection activities are tedious and don’t require a lot of creative thinking. Rules engines can be programmed to take care of these tasks by themselves, freeing up FI employees for cases where more subjective judgment is needed.
- Handles speed and volume: Rules engines allow FIs to analyze transactions at scale and take action on anything suspicious near-instantaneously, something humans can’t do.
- Reduces human error: As long as a rules engine’s rules are set up correctly, they will execute the same way every time. This eliminates the possibility of a human making a mistake by doing a process manually.
- Aids regulatory adherence: FIs can tune their rules engines to work in accordance with specific AML regulations that need to be followed. This reduces the possibility of the FI’s anti-fraud and AML activities being found non-compliant.
- Increases compliance transparency: A rules engine allows an anti-fraud and AML team to see records of what decisions were made on activities, and why. This allows the team to adjust the rules for better accuracy to avoid false positives and false negatives. It also helps during audits to clearly explain how the FI’s anti-fraud and AML processes work.
Different Types of Rules for Detecting and Preventing Fraud and Money Laundering
Not every anti-money laundering and anti-fraud rules engine works the same way, because not all rules work the same way within a rules engine. Some are very cut-and-dry, while others prioritize certain criteria over others in deciding what activities are or aren’t suspicious. Here are a few categories of them, to illustrate.
Logic Conditions
Logic conditions are the most basic rules for fraud and money laundering detection. They consist of a series of steps that check, one-by-one, whether the criteria at each step are all present, partially present, or not present in an event. Depending on the result at each step, the rules may perform different checks and end up executing different actions.
Logic conditions are best used for when certain criteria are explicitly required, like those spelled out in applicable regulations.
Risk Scoring
Risk scoring is a more advanced form of money laundering and fraud detection rulemaking. It assigns a value or “weight” to each criterion, based on how likely the presence (or absence) of that criterion indicates a suspicious activity. It then checks an event against all applicable criteria, then adds up the values to see if the total lands above a certain threshold. If it does, the rules engine will trigger an alert and tell anti-fraud or AML operatives how likely it is that the event is suspicious.
Risk scoring—often referred to as alert scoring—is a more nuanced way to check if a transaction may be fraudulent. It can result in fewer false positives and false negatives if done correctly, but it requires greater human interpretation of what is or isn’t considered risky.
Signal Aggregation
Signal aggregation is like a more large-scale version of risk scoring. It collects multiple evaluations of an event and averages its outcomes to determine what action(s) to take. So it can be even more accurate and consensus-building than risk scoring in identifying suspicious activity. However, it requires finding evaluation sources to work off of, and may also involve making subjective judgments on which sources are more reliable or “weighty” than others.

Use Unit21’s No-Code Rules Engine to Detect and Prevent Fraud
Unit21’s Transaction Monitoring tool uses a rules engine centered around risk scoring. It evaluates not only information pertaining to the transactions themselves but also data that contextualizes the transactions. This includes aspects such as who’s initiating them, where they’re being initiated from, and how often they’re being initiated. And it does this all without a compliance team having to write a single line of computer code.
Risk and compliance teams can use this to develop predefined rules that signal when cases should be investigated for fraud or money laundering, and can even be used to take immediate action on a case (by halting a transaction in process, for example).
Book a demo with us today to see it in action.