
Black-Box Machine Learning
How the Model Works & Top Benefits
Since its development, machine learning has been used for a number of different applications – including fraud detection. White-box machine learning is helpful for detecting and doing in-depth analyses of known fraudulent activity patterns.
But what if a risk management team wants to look for new signs of fraud? Or it has too many cases and not enough time to do thorough investigations into all of them? That’s where black-box machine learning can be handy.
This article will give a black-box machine learning definition and explain how the concept works. It will also discuss black-box machine learning in relation to white-box machine learning, including where it is better to use one or the other.

What is Black-Box Machine Learning?
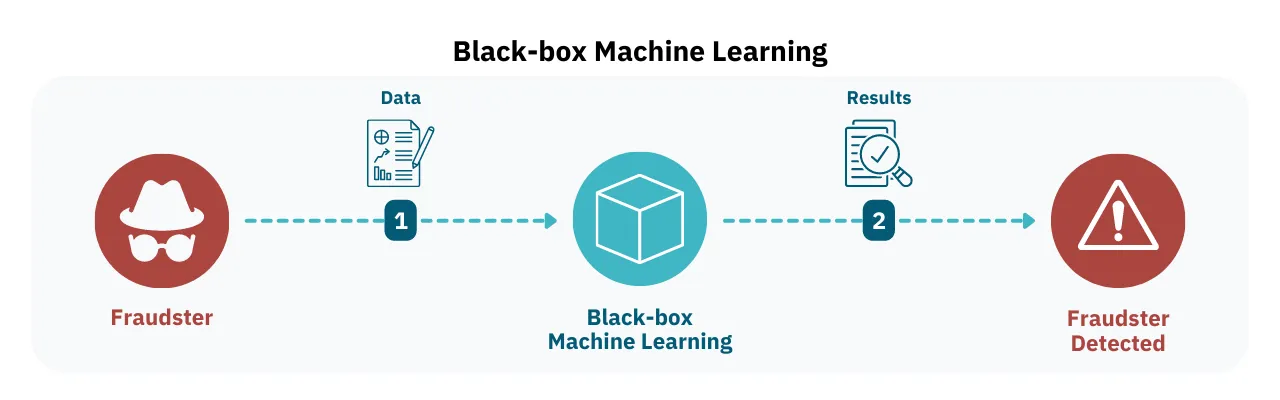
Black-box machine learning is an artificial intelligence model where the process by which an algorithm analyzes data and returns a conclusion is not shown. That is, the user is forced to trust that the algorithm’s logic works properly, and will therefore come to a correct conclusion.
A black-box approach to machine learning tends to work quickly, and is able to intuitively pick up patterns and anomalies that humans likely wouldn’t otherwise catch. However, it’s difficult to tune because its decision-making process is opaque. That means users have to look at how it responds to different scenarios in order to make an educated guess as to how it’s coming to its conclusions, and then make changes from there.
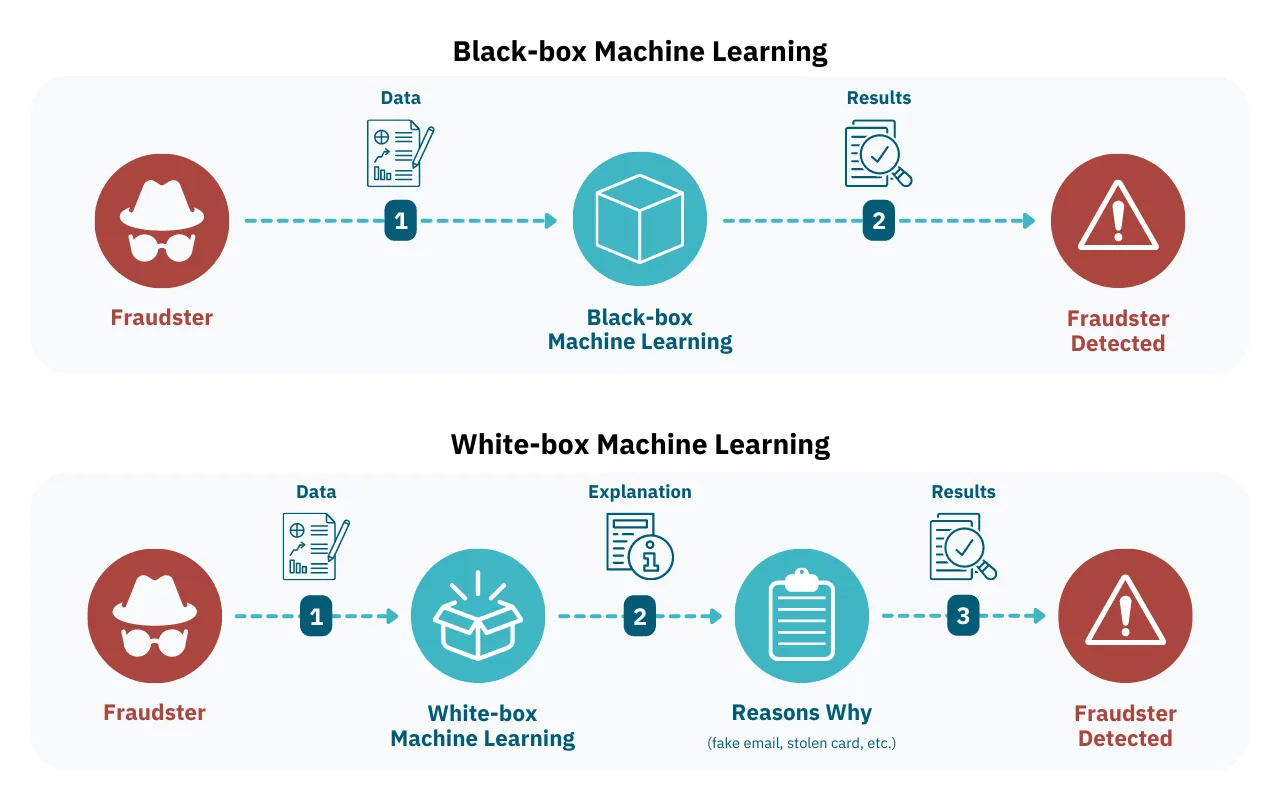
This contrasts white-box machine learning, which displays all the decisions it makes in answering any problem it’s given. This allows users tighter control over how the algorithm “thinks” so they can adjust it to reach specific outcomes reliably.
How Does a Black-Box Machine Learning Model Work?
Black-box machine learning algorithms tend to be more common than white-box ones. They work by ingesting sample data to discover patterns and anomalies, then writing rules for detecting and making decisions on them. Then they are fed data regarding specific scenarios, and use the rules they’ve developed to determine answers to these questions.
Step 1: Training the algorithm with sample data
First, users have to give the algorithm massive amounts of data related to the types of questions they’re going to ask. This lets the algorithm explore the data to find patterns and anomalies. In doing so, the algorithm begins to create rules for when to make or not make certain distinctions.
Step 2: Asking a question by inputting data specific to a real-world scenario
The next step is to give the algorithm data related to a particular practical situation. Then the algorithm will make decisions based on the rules it has created to produce a result.
Step 3: Getting a result from the algorithm
The black-box algorithm will produce a result based on the data it’s given, but it won’t reveal how this was done. Unlike white-box algorithms, a black-box one won’t reveal which decisions were made or what factors were considered in making those decisions.
Step 4: Making adjustments based on multiple outcomes
A black-box machine learning model is able to use the context-specific data it’s fed to continue to learn and adjust itself beyond the training data. Users can make changes manually as well, but because a black-box model’s processes are hidden, this is much more difficult than it is with white-box models.
So to make manual changes, users often have to run multiple tests using different scenarios and see how the black-box model responds to them. Then, based on the outcomes, users must make educated guesses about how the model needs to be adjusted. This is further complicated by the fact that each scenario run can slightly alter the algorithm.
Black-Box vs. White-Box Machine Learning
Black-box machine learning models are often compared against white-box models. Black-box models are generally faster and more exploratory than white-box ones. However, it’s more difficult to train them to reach specific outcomes, as they do not reveal their decision-making processes like white-box models do.
The table below contains a quick summary of black-box vs. white-box machine learning.
White box models can be useful in situations where it is essential to understand how the model is making its predictions. This can be especially important in fraud or AML cases where legal or ethical issues may arise from using the model, as it allows for greater transparency and accountability.
The Benefits of a Black-Box Machine Learning Model
When trying to determine whether to use a black-box algorithm for machine learning or a white-box one, there are certain situations in which black-box models are preferred.
Despite their lack of transparency, black-box models can work better when:
- Results are needed quickly, especially when analyzing very large datasets
- It’s acceptable for the algorithm to work unsupervised, without users needing to adjust it in order to reach specific outcomes
- Users prefer the algorithm to discover new patterns and anomalies on its own, rather than try to identify known patterns based on pre-existing rules

Use Black-Box Machine Learning to Prevent Fraud
Fraudsters are constantly coming up with new ways to swindle businesses – tactics, techniques, and procedures that may not always be caught by a business’s existing anti-fraud measures. That’s why it can be useful for a business to use a black-box algorithm in machine learning, in addition to a white-box one.
The white-box model can be tuned to detect known fraudulent activity patterns. Meanwhile, the black-box one can be used to explore data in order to find other instances of suspicious behavior that may be part of new fraud schemes.
While machine learning solutions (either black-box or white-box) are useful for certain applications, they aren’t a be-all-end-all solution. Risk scores help teams hone in on what to investigate, but they are often more reactive than they are proactive. To actually prevent fraud, you need a rule-based engine that lets you easily manage (and adjust) internal controls.